
 热点
热点




微信公众号

微信小程序

【摘要】 4月20日,在Morketing联合亚马逊AWS举办的“云计算撬动的数字营销”高端研讨会上,TalkingData高级运维总监潘松柏介绍了数据科学,大数据环境对Administrator的挑战,数据沙箱,TD沙箱的流程和产出架构等方面的问题
TalkingData 高级运维总监 潘松柏
截止2016年2月,TalkingData在整个互联网累计设备是30亿,日活跃设备数2.5亿,月活跃设备数6.5亿,每天数据的新增量大概是14T左右,每天交互会话量达34亿,每天处理事件数达370亿。线下还有一些WIFI采集点,覆盖了大概80个一线城市或者二线城市,商城3000个,WIFI指纹400万,位置信息4200万。目前主要覆盖了金融,房地产、汽车、零售、医疗、航空、酒店等行业。

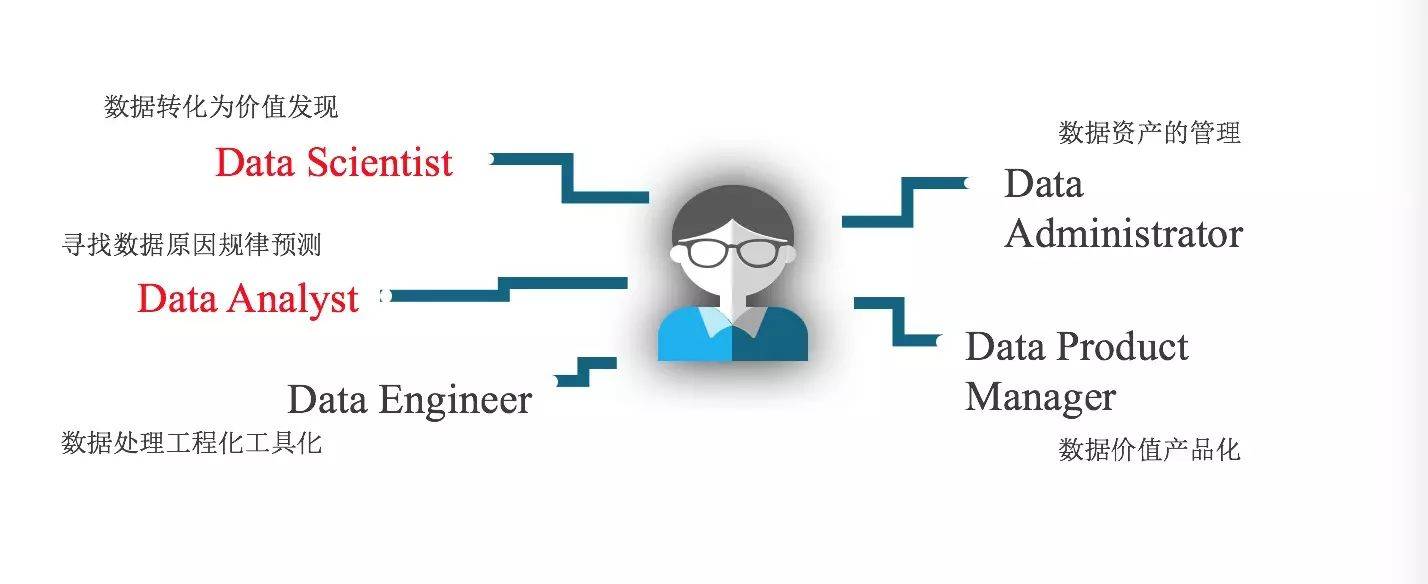
最近两年讲到一个新名词:数据科学。有些企业也在招聘自己的数据科学家。大数据行业目前分工越来越细。从分工上可以分为数据科学和数据分析:数据科学是把数据转化为价值发现,从另外一个角度来说这是一项艺术,而不能说是技术;而数据分析则是寻找数据原因、规律,包括未来的数据预测。实际上在很多企业里,这两个职位可能是一个人,或者是一个团队。这两年才有的大数据工程师,例如hadoop工程师、spark工程师、或者是写Python语言、R语言的工程师,这些数据工程师数据的处理,负责大数据下工程化、工具化。
在金融行业或传统的大数据行业中,大技术场景下工程师的工作细分为两种:数据资产管理员和数据产品经理。数据资产管理员会更关注整个数据circle,会从数据的产生、数据的中间处理过程、数据的最终访问、以及数据最后的销毁等等。而数据产品经理更关注前面所产生的一系列结果,然后把数据相关的资产进行数据价值产品化,比如大数据营销,是把整个数据生态进行产品化。今天所讲的Sandbox只包括Data Scientist和Data Analyst,所以是一个比较小众的技术。
大数据产品下的技术挑战
这是现在大家都面临的问题。由于互联网技术的开放,包括分布式计算技术的开放,我们面临着数据量庞大的问题,尤其是数字行业中造成很大的用户行为轨迹,移动设备产生的数据等,这种数据体量超过了前几十年数据的增长。处理数据上的问题是计算资源的消耗大,IT成本上开销很大。因为本身数据量大,采用分布式计算,所以会分发到所有的计算资源进行工作,后期再汇总。这样导致大数据处理的耗时比较长。最后一个问题是在大数据场景下,计算过程中发现数据处理的结果没有办法预期。例如计算中出现中断,想计算出来的结果和最终计算出来的结果产生一系列的偏差等等,都是一系列的挑战。
数据沙箱
在讲大数据沙箱的时候,在计算机安全领域,沙箱又名沙盒(英语:sandbox)是一种安全机制,为执行中的程序提供隔离环境,通常是作为一些来源不可信,具破坏力或者无法判定的程序意图提供实验环境。数据沙箱中要能有真实的数据,还需要在真实的数据上快速试错。
处理数据沙箱的几个原则
首先是数据真实性,在大量的数据中进行数据采样,如何尽可能多的覆盖到需要的数据点;以及数据噪点,怎样通过数据采样,做数据的过滤。
第二个是数据的安全性,数据沙箱不光是企业内部使用,还开放给合作伙伴,甚至是科研机构,他们可以把自己的数据放进沙箱和我们的数据进行融合,根据我们自己在上面形成的数据算法得到他们想要的数据或未知的探索性的东西,所以我们需要做物理隔离。同时我们还需要计算资源隔离,例如有30个用户,把30个用户放在一个沙箱里面时数据和计算资源会出现争抢。每个用户的需求是不一样的,有的需要位置数据,有的需要用户行为数据,所以需要进行数据隔离。当然还要进行租户管理,我们需要针对于租户不同的特性做不同的资源隔离、不同的资源管理。
第三是时间窗口,在沙箱里提供足够的资源,适合其场景的资源做计算,用户可以快速的试错,按照他们预期的时间得到想要的结果。而我们需要尽可能低的成本,而且按照用户的定制需求去增配。
EC2 VS Docker 优缺点对比
在做沙箱之前,针对目前比较流行的容器做了对比。在EC2上定制镜像时,它支持AMI,即可以提交自己定制的OS镜像,而Docker则是有自己的Docker img。目前我们没有计费策略,在开放给用户或企业的时候,需要对用户的沙箱单独计费,计算需要更细,按小时、按分钟去计费,如果是自建容器就不支持。
沙箱所解决的问题
在整个数据处理的过程中,沙箱是在整个闭环过程中,数据科学人员能够快速的验证自己的数据想法并且加以修正,为下面的大规模数据加工处理提供建模和算法依据。例如你在沙箱中根据用户的行为轨迹去判断常规的活动点,根据小的数量集能够快速的反馈,而且能够按照这种方式定制自己的算法和模型,后期数据工程师在处理数据时,可以根据这种算法模型处理大规模的数据。
混合云的优势
TD的沙箱模型是在混合云大的架构下,目前我们和AWS通过系统运营商的专线进行打通,和自己base于在北京以及异地的数据云打通,一方面保护数据的私有性,另一方面在大的环境下保证数据的安全性。混合云这种架构可能更适合我们,很多企业也会有这种需求。第一我们可以利用公有云的权限管理,定制多租户的场景。刚才提到了爆量的问题,我们现在有很多新的业务会从测试环境、开放环境迁移到生产环境中来,前期的话用户量没有办法预测,我们基本上像这种业务首先放在公有云上,公有云稳定之后再考虑。公有云抗攻击能力比较强,像Paas、rds、elb等成熟的组件可以直接使用,而且可以按照自己的业务场景定制。公有云的权限和计费详单API结合在一起,对多租户的情况单独进行计费。
沙箱的基础流程
在页面上用户可以输入自己的模型或提交自己的数据,在提交数据的时候,会选择需要用到TD的哪些数据,我们会通过后端的ETL后台数据直接抽取,根据数据属性ETL会通过零散的数据抽取,比如需要一个月的数据,则抽取的是每个月抽取100条,如果选择多维度数据,也会有相应的算法,帮你从TD里抽取离散数据。另外在前端可以定制你的集群方式:单机模式、集群模式。通过AWS API,形成单机和集群模式。单机和集群模式通过前端输入的参数,通过再加一些外围的脚本,然后进行整个环境、整个沙箱的初始化,数据采集中我们会把整个S3的存储路径存储到数据化环境里。因此产生的环境是带有数据属性位置的环境,可以在上面做自己的训练集,做自己想法的预测,然后产生的数据模型输入结果。大家用沙箱的时候,在AWS端会存储OS镜像,第二天需要继续工作时,通过案件沙箱里面的服务就会再次启动。
Td-library 产出架构
我们做了Td-library,除了提供基础平台,还有算法能力和算法服务的提供。算法服务方面,有lookalike营销人员放大,X-means人群划分研究。算法能力方面,我们做了Fregata——一个分布式大规模机器学习的算法库,目前已经开源了;Smile是基于JAVA的中小规模机器学习库;还有点对点的算法——Micheal End-to-End机器学习方法,其中Micheal 是去年在kaggle比赛的第一名写的深度学习算法,end to end 是端到端,深度学习的一个特征。
一、基础平台:数据科学平台
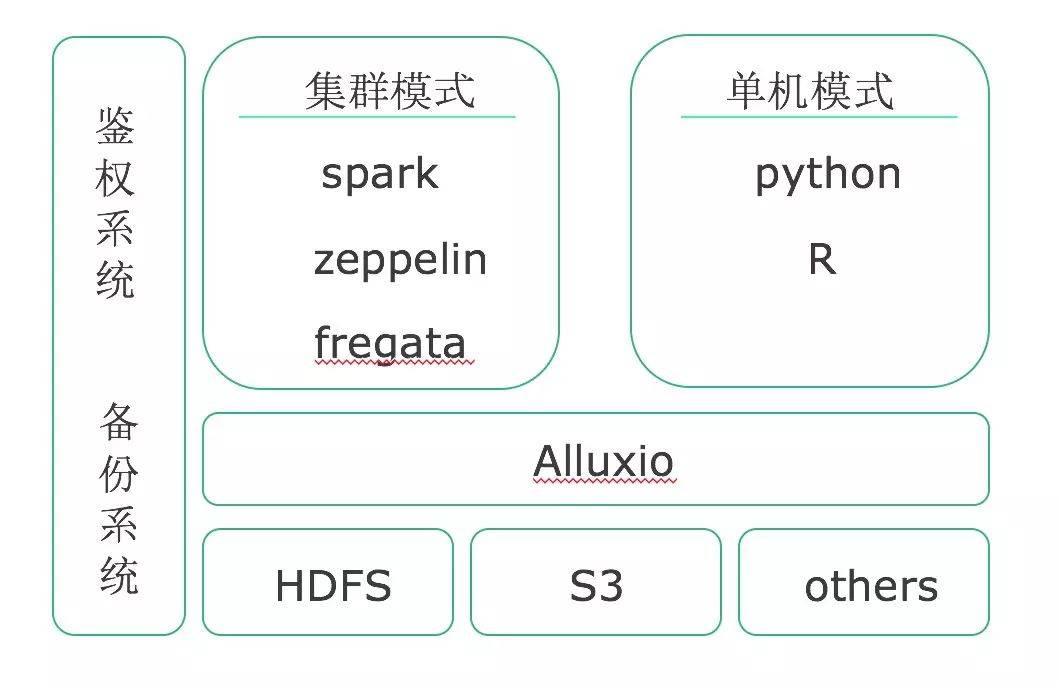
基础平台底层的存储基本上是三块,像HDFS、S3、还有其他的一些存储。为了保证沙箱的运算速度,在中间加了一层Alluxio缓存层。在整个计算资源分配上会用到spark、zeppelin、fregata,我们还集成了Python和R语言,这样更适合数据科学人员以及模型建模人员使用。旁边的鉴权系统和备份系统则用到了AWS。
二、算法能力
我们拥有大规模和中小规模机器自主研发算法包,其中大规模机器学习可支持上万亿维度的逻辑回归,同时还支持parameter free,拥有分类,聚类,推荐等主流算法。
我们还拥有End-to-End计算框架,使用Tensorflow 做基础框架,只用GPU加速,在某些算法上直接调用Cuda接口进行计算。
三、服务能力
Lookalike:支持大规模机器学习,异步计算在分钟级输出结果,可用于人群放大和维度分析。X-means:支持大规模机器学习,可供用户分析用户属性。
 点赞 0
点赞 0 收藏 0
收藏 0 转发
转发 微信公众号
微信小程序





 公众号
公众号 意见反馈
意见反馈
请先注册/登录后参与评论